Ever since I studied Shannon and Weavers's classic paper on information theory and studied entropy as a chemistry major - I have been interested in the flow of information in biological systems. With the advent of modern techniques it is now possible to study the DNA of entire organisms (genomics), the collection of all RNA gene readouts in a cell (transcriptomics), the resulting protein locations, concentrations, turnover and post translation modifications (proteomics), and all of the small molecules within these systems (metabolomics). There are a large number of studies in all of these areas across medicine in general but also psychiatry and addiction. Before I launch into some of these studies I thought I would address a basic question I get from colleagues that looks at basically the genomic approach to drug metabolism.
One of the most common questions I get from colleagues and online is: "Do you think that genetic testing is necessary? Do you think it is useful?" My standard response has been that in some cases it is but most of the time it is unnecessary. I also point out that I am old school and that plasma levels of antidepressants seem to be more of an accurate approach to antidepressant therapy. The debate at the about plasma levels is always whether there is a known therapeutic level or not. A lot of that debate dates back to the 1980s when we were using tricyclic antidepressants. Psychiatrists typically used nortriptyline because the therapeutic levels were well defined. Clinical trials data at the time provided therapeutic levels for all of the major tricyclics (amitriptyline, imipramine, desipramine). Clinical chemistry companies also provided levels for less commonly used tricyclics like doxepin and trimipramine quoting smaller trials or observational studies for the therapeutic levels. All of these drugs had toxic levels because of studies done on drug overdoses using these drugs. A psychiatrist would typically get back a report with a quoted therapeutic level (or proposed levels), active metabolite levels, and toxicity levels. In the case of a drug with no metabolites like nortriptyline the report would give the level, the range, and a much higher toxicity range.
When we entered the human genomics era there was expanded interest in the genetic bases of the pharmacokinetics (PK) and pharmacodynamics (PD) of psychiatric drugs. That involved understanding the genetics of the hepatic cytochromes that metabolize most drugs and the genetics of the protein targets (reuptake proteins and receptor sites) where the drugs had their purported effects. Most of the pharmacogenomics of drug metabolism is focused on PK rather than PD.
One of the best independent reviews of the issue of genetic testing can be found in reference 3 below. The authors do a systematic review looking at the question and come away with 5 clinical trials that look at the efficacy of commercially available pharmacogenomic testing and 5 studies that look at the issue of cost-effectiveness.
Test
|
Type
|
GeneSight
|
Combinatorial
|
Genecept Assay
|
Combinatorial
|
CNSDose
|
Combinatorial
|
Combinatorial in this case means testing for multiple genes and it has been shown to currently be more predictive of antidepressant response than any single test. Each of the assays typically looks at gene loci involved in drug metabolism and flags markers at that site. For example, I took my 23&Me data and ran it through a second software site that yielded the following analysis:
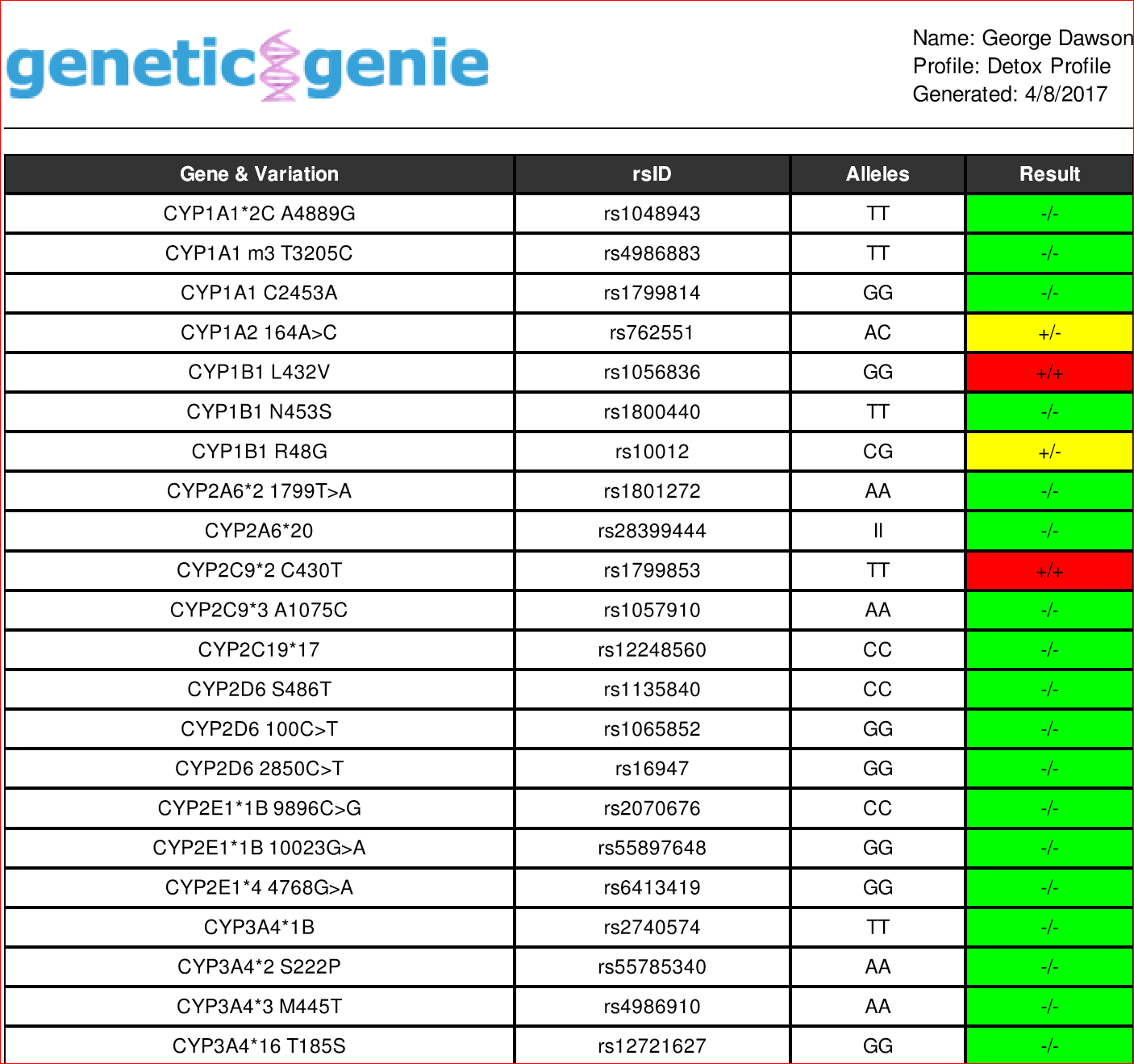
The CYP pharmacogenes on the left are associated with drug metabolism. The rsID in column 2 designates the single nucleotide polymorphism noted in that gene. Alleles are just different gene forms based on the difference at a single locus. In this chart nucleotide bases (A.T,G,C) are designated. The result column notes if the genes have mutations (+) or not (-) and are homozygous (+/+, -/-) or heterozygous (-/+). The red color code is homozygous for the mutation and the yellow color code is heterozygous.
In the above chart. red color codes for deficiencies in drug metabolism. For example, the
rs1799853 on the pharmacogene CYP2C9*2 C430T (TT) is associated with a 40% reduction in warfarin metabolism and a greater risk for NSAID metabolism. In fact, I was treated briefly with warfarin - had a difficult time with dose adjustments and was physically ill from the medication.
What about the common drug metabolizing genes? In the case of common genes like CYP2C19 and CYP2D6 several variants are flagged and none of the variants are detected. In terms of drug metabolism, the following results could be expected if they were found:
CYP2C19*17 (rs12248560) CC - normal genotype, CT - ultrafast metabolizer, TT - ultrafast metabolizer
CYP2D6 S486T (rs1135840) CC - normal variant studied in clozapine metabolism
CYP2D6 100C>T (rs1065852) GG - variant (C;T)(T;T) variants are associated with non functioning CYP2D6
CYP2D6 2850C>T (rs16947) GG - normal variant - other variants may be associated with ultra-rapid CYP2D6 metabolism
These examples illustrate that SNPs can result in non-functioning CYP enzymes that would lead to an accumulation of the target drug or in some cases ultra-metabolism of the target drug with lower than expected plasma levels or in some cases physical effects from rapidly decreasing plasma levels. There are a finite number of SNPs studied in this approach and a relevant question is what is the total universe of clinically relevant SNPs for a particular pharmacogene. For example, in the PharmVar database database tables are available for CYP2D6 that give the frequencies of 113 alleles across all major race and ethnic groups. A separate table lists 140 haplotypes with 993 variants. 39% of the variants are decreased function or no function alleles (54/140), 20% were normal (28/140), and 34% were unknown (48/140).
A recent study (4) looks at the practical aspects of predicting drug metabolizing phenotype from available CYP2D6 genotypes. This is essentially the task of consumer pharmacogenomic testing. Thuis study has the additional advantage of applying uniform methodologies across a large number of samples (N=104,509) instead of the small samples and non-uniform methodologies often used in typical databases. They looked at both single nucleotide variants (SNVs) and copy number variants (CNVs) like gene duplications, deletions of entire CYP2D6 genes, and gene rearrangements. CYP2D6 copy numbers of 0, 1, 2, 3 or > 3 were assigned. Metabolizer status was assigned based on copy number with: Ultrarapid metabolize (UM ≥ 3 normal functioing gene copies); normal metabolizer (NM, 1 or 2 normal functioing alleles), intermediate metabolizer (IM, ≥ 2 decreased functioing alleles), and poor metabolizer (PM, ≥ 2 no function alleles).
37 CYP2D6 alleles were detected in the sample including 23 structural variants. 13.1% of the sample had copy number variants (CNVs). The majority of structural variants had no function due to CYP2D6*5 gene deletion. 93% of the alleles were single copy variants with normal function (62%). Based on the above convention phenotypic predictions were 2.2% Ultrarapid Metabolizers (UM), 81.4% Normal Metabolizers (NM), 10.7% intermediate metabolizers (IM), and 5.7% poor metabolizers (PM). The authors point out that copy number variants (CNVs) contribute to significant variance in drug metabolism and may be underestimated in a number of studies. They also point out that there are no current standards to predict genotypes from phenotypes. The importance of CNVs in phenotypic variation is captured by this graphic from the original reference (4):
Getting back to the study in reference 3, the authors looked at what genes were studied in the commercial tests. Genesight looked at 6 genes (CYP2D6, CYP2C19, CYP1A2, CYP2C9, serotonin transporter gene (SLC6A4) and serotonin 2A receptor gene (HTR2A). The authors review 2 unrandomized studies of major depression by the same primary author comparing a group guided by the Genesight to a group that was not. There were increased improvement in depression scores in the Genesight guided group. A separate randomized study of Genesight guidance versus treatment as usual showed greater improvement in depression scores but no statistical significance.
CYP2C19*17 (rs12248560) CC - normal genotype, CT - ultrafast metabolizer, TT - ultrafast metabolizer
CYP2D6 S486T (rs1135840) CC - normal variant studied in clozapine metabolism
CYP2D6 100C>T (rs1065852) GG - variant (C;T)(T;T) variants are associated with non functioning CYP2D6
CYP2D6 2850C>T (rs16947) GG - normal variant - other variants may be associated with ultra-rapid CYP2D6 metabolism
These examples illustrate that SNPs can result in non-functioning CYP enzymes that would lead to an accumulation of the target drug or in some cases ultra-metabolism of the target drug with lower than expected plasma levels or in some cases physical effects from rapidly decreasing plasma levels. There are a finite number of SNPs studied in this approach and a relevant question is what is the total universe of clinically relevant SNPs for a particular pharmacogene. For example, in the PharmVar database database tables are available for CYP2D6 that give the frequencies of 113 alleles across all major race and ethnic groups. A separate table lists 140 haplotypes with 993 variants. 39% of the variants are decreased function or no function alleles (54/140), 20% were normal (28/140), and 34% were unknown (48/140).
A recent study (4) looks at the practical aspects of predicting drug metabolizing phenotype from available CYP2D6 genotypes. This is essentially the task of consumer pharmacogenomic testing. Thuis study has the additional advantage of applying uniform methodologies across a large number of samples (N=104,509) instead of the small samples and non-uniform methodologies often used in typical databases. They looked at both single nucleotide variants (SNVs) and copy number variants (CNVs) like gene duplications, deletions of entire CYP2D6 genes, and gene rearrangements. CYP2D6 copy numbers of 0, 1, 2, 3 or > 3 were assigned. Metabolizer status was assigned based on copy number with: Ultrarapid metabolize (UM ≥ 3 normal functioing gene copies); normal metabolizer (NM, 1 or 2 normal functioing alleles), intermediate metabolizer (IM, ≥ 2 decreased functioing alleles), and poor metabolizer (PM, ≥ 2 no function alleles).
37 CYP2D6 alleles were detected in the sample including 23 structural variants. 13.1% of the sample had copy number variants (CNVs). The majority of structural variants had no function due to CYP2D6*5 gene deletion. 93% of the alleles were single copy variants with normal function (62%). Based on the above convention phenotypic predictions were 2.2% Ultrarapid Metabolizers (UM), 81.4% Normal Metabolizers (NM), 10.7% intermediate metabolizers (IM), and 5.7% poor metabolizers (PM). The authors point out that copy number variants (CNVs) contribute to significant variance in drug metabolism and may be underestimated in a number of studies. They also point out that there are no current standards to predict genotypes from phenotypes. The importance of CNVs in phenotypic variation is captured by this graphic from the original reference (4):
 |
| Figure 6. Contribution of structural variants and single copy variants to predicted phenotypes. Proportion of individuals in each predicted phenotype that had at least one structural variant is shown (from reference 4). |
Getting back to the study in reference 3, the authors looked at what genes were studied in the commercial tests. Genesight looked at 6 genes (CYP2D6, CYP2C19, CYP1A2, CYP2C9, serotonin transporter gene (SLC6A4) and serotonin 2A receptor gene (HTR2A). The authors review 2 unrandomized studies of major depression by the same primary author comparing a group guided by the Genesight to a group that was not. There were increased improvement in depression scores in the Genesight guided group. A separate randomized study of Genesight guidance versus treatment as usual showed greater improvement in depression scores but no statistical significance.
Genecept was another commercially available studied product that was used 2 clinical trials. Genecept looks at CYP2D6, CYP2C19, CYP3A4, SLC6A4, 5HT2C, DRD2 (dopamine-2receptor), CACNA1C (L-type voltage gated calcium channel), ANK-3 (ankyrin g, COMT (catechol-O-methyl transferase, and MTHFR (methylenetetrahydrofolate reductase). The first was a naturalistic study with no control group (N=685) and all subjects got genetic testing. 77% of participants improved - 39% with improved scores and 38% with remitted depression.
CNSDose was the final assay that was studied clinically. This assay looks at CYP2D6, CYP2C19, and ABCC1 and ABCB1 (blood brain barrier transporters). This was a prospective double blind randomized guided versus unguided study (N=148). Guided subjects had a 72% remission rate compared with the 28% remission rate in the unguided group or a 2.52-fold greater chance of recovery. It was unclear how the guidance resulted in such high remission rates and the study has not been replicated.
The authors go on to review similar problems with cost-effectiveness analysis applied to the currently available genetic tests. They also review the methodological limitations of the current studies and conclude that pharmacogenomic testing is generally not ready for prime time at this point for most clinical psychiatrists. That is what I have been saying for years - along with advocating for plasma levels of antidepressants and antipsychotics when they are available. That said - I have done pharmacogenomic testing for patients who do not tolerate antidepressant medications or seem to be experiencing atypical side effects - like discontinuation symptoms the same day from SSRI or SNRI antidepressants that usually do not cause those symptoms.
Striking features from this brief review include the apparent lack of standard rules on interpreting drug metabolizing phenotype from genotypes and the importance of copy number variants in predicting phenotype. If clinicians are getting genotyping for genotyping predictions it is a good idea to make sure that these genotypes are also determined in addition to the single nucleotide variants. Specific genes in reports can all be looked up for specifics based on the rsID located in this post.
Given these constraints, I think that commercially available pharmacogenomics assays need to be very explicit on how they determine drug metabolizing phenotypes, what genetic information they are actually measuring, and what might be missed. The ultimate clinical trial would be to look at a group of patients who did not tolerate specific antidepressants and see if higher than expected abnormal drug metabolizer frequencies could be detected.
George Dawson, MD, DFAPA
References:
1: Weinshilboum RM, Wang L. Pharmacogenomics: Precision Medicine and Drug Response. Mayo Clin Proc. 2017 Nov;92(11):1711-1722. doi: 10.1016/j.mayocp.2017.09.001. Epub 2017 Nov 1. Review. PubMed PMID: 29101939.
2: Wang L, McLeod HL, Weinshilboum RM. Genomics and drug response. N Engl J Med. 2011 Mar 24;364(12):1144-53. doi: 10.1056/NEJMra1010600. Review. PubMed PMID: 21428770.
3: Rosenblat JD, Lee Y, McIntyre RS. Does Pharmacogenomic Testing Improve Clinical Outcomes for Major Depressive Disorder? A Systematic Review of Clinical Trials and Cost-Effectiveness Studies. J Clin Psychiatry. 2017 Jun;78(6):720-729. doi: 10.4088/JCP.15r10583. Review. PubMed PMID: 28068459.
4: Del Tredici AL, Malhotra A, Dedek M, Espin F, Roach D, Zhu G, Voland J and Moreno TA (2018) Frequency of CYP2D6 Alleles Including Structural Variants in the United States. Front. Pharmacol. 9:305. doi: 10.3389/fphar.2018.00305
Relevant Databases:
1: Transformer Database (formerly Super CYP Database).
Michael F. Hoffmann, Sarah C. Preissner, Janette Nickel, Mathias Dunkel, Robert Preissner and Saskia Preissner. The Transformer database: biotransformation of xenobiotics. Nucleic Acids Res. 2014 Jan 1;42(1):D1113-7. doi: 10.1093/nar/gkt1246. Epub 2013 Dec 10.
Given these constraints, I think that commercially available pharmacogenomics assays need to be very explicit on how they determine drug metabolizing phenotypes, what genetic information they are actually measuring, and what might be missed. The ultimate clinical trial would be to look at a group of patients who did not tolerate specific antidepressants and see if higher than expected abnormal drug metabolizer frequencies could be detected.
George Dawson, MD, DFAPA
References:
1: Weinshilboum RM, Wang L. Pharmacogenomics: Precision Medicine and Drug Response. Mayo Clin Proc. 2017 Nov;92(11):1711-1722. doi: 10.1016/j.mayocp.2017.09.001. Epub 2017 Nov 1. Review. PubMed PMID: 29101939.
2: Wang L, McLeod HL, Weinshilboum RM. Genomics and drug response. N Engl J Med. 2011 Mar 24;364(12):1144-53. doi: 10.1056/NEJMra1010600. Review. PubMed PMID: 21428770.
3: Rosenblat JD, Lee Y, McIntyre RS. Does Pharmacogenomic Testing Improve Clinical Outcomes for Major Depressive Disorder? A Systematic Review of Clinical Trials and Cost-Effectiveness Studies. J Clin Psychiatry. 2017 Jun;78(6):720-729. doi: 10.4088/JCP.15r10583. Review. PubMed PMID: 28068459.
4: Del Tredici AL, Malhotra A, Dedek M, Espin F, Roach D, Zhu G, Voland J and Moreno TA (2018) Frequency of CYP2D6 Alleles Including Structural Variants in the United States. Front. Pharmacol. 9:305. doi: 10.3389/fphar.2018.00305
Relevant Databases:
1: Transformer Database (formerly Super CYP Database).
Michael F. Hoffmann, Sarah C. Preissner, Janette Nickel, Mathias Dunkel, Robert Preissner and Saskia Preissner. The Transformer database: biotransformation of xenobiotics. Nucleic Acids Res. 2014 Jan 1;42(1):D1113-7. doi: 10.1093/nar/gkt1246. Epub 2013 Dec 10.
Preissner S, Kroll K, Dunkel M, Senger C, Goldsobel G, Kuzman D, Guenther S, Winnenburg R, Schroeder M, Preissner R. SuperCYP: a comprehensive database on Cytochrome P450 enzymes including a tool for analysis of CYP-drug interactions. Nucleic Acids Res. 2010 Jan;38(Database issue):D237-43. doi: 10.1093/nar/gkp970. Epub 2009 Nov 24. PubMed PMID: 19934256
2: Pharmacogene Variation (PharmVar) Consortium (formerly Human Cytochrome P450 (CYP) Allele Nomenclature Database).
Table of pharmacogenomic markers in drug labeling.
Other FDA resources related to pharmacogenomics.
FDA Precision Medicine site.
4: CPIC (The Clinical Pharmacogenetics Implementation Consortium) web site.
CPIC Alleles
CPIC Genes-Drugs
Graphics Credit:
Structural Variant versus Predicted Phenotype graphic is from reference 4 above and is unaltered. It is used per the Creative Commons Attribution 4.0 International Public License.